In which various tools and methods are explored for analyzing data that describes a network of complaints against NYPD officers (or any other PD with similar public data)
Finding Clusters of NYPD Officers In CCRB Complaint Data
Why?
Complaints filed against police officers by the public are often the first and only warning sign that a cop might be on a course of escalating violence.
In the deaths of George Floyd and Eric Garner their killers had a documented history of complaints filed against them. Unfortunately nothing was done to disrupt their pattern of abuse, and both cases ended in those officers killing members of the public they had sworn to protect.
George Floyd
Chauvin, who was fired, has said through his attorney that his handling of Floyd’s arrest was a reasonable use of authorized force. But he was the subject of at least 22 complaints or internal investigations during his more than 19 years at the department, only one of which resulted in discipline. These new interviews show not only that he may have used excessive force in the past, but that he had used startlingly similar techniques.
'That could have been me': The people Derek Chauvin choked before George Floyd
The officer convicted of murdering George Floyd had at least 22 complaints against him. The officer who put Eric Garner in a chokehold and killed him had 7 complaintsfiled against him.
Eric Garner
Before he put Garner in the chokehold, the records show, he had seven disciplinary complaints and 14 individual allegations lodged against him. Four of those allegations were substantiated by an independent review board.
The disturbing secret history of the NYPD officer who killed Eric Garner
Of the 14 individual allegations against Garner's killer, 5 are for force: "hit against inanimate object", "physical force", and a single complaint in 2014 that would foreshadow the behavior that would eventually end the Officer's career: "Force - Chokehold".
I am documenting my analysis in detail for a few reasons:
So that other people who may want to perform similar analysis for other Police Departments can understand and recreate my analysis
So that every step is documented, and any mistake can be easily caught and fixed by the infinite supply of people on the internet who are smarter than me
To maybe inspire people to use computers to investigate the things in the world that are important to them, and share the tools I use to do that
Network visualization prior work / inspiration
You may have seen network analysis like this before.
Adi Cohen has pioneered a method of combining Gephi with CrowdTangle to analyze the network of groups and pages sharing links.
Provenance
WNYC/Gothamist received the data in response to a Freedom of Information Law request and provided me an excel file for analysis.
The Dataset
Differences from data previously released by ProPublica
ProPublica released and covered similar data in July of 2020.
They chose to only publish data for "active-duty officers who’ve had at least one allegation against them substantiated by the CCRB".
The dataset we are working with today contains every complaint and officer, even those with no substantiated allegations.
It also contains officers who were listed as witnesses on complaints, including complaints found as "unsubstantiated" or "unfounded" by the CCRB.
This makes it a "noisier" dataset. In our case this can be an advantage since we are looking to visualize the network of officers.
Being named with another officer on a complaint, even if that complaint is unfounded, is a signal that those officers interacted in a way that was noticed by the public. Being the subject of an unfounded complaint together might even cause officers to form a tighter relationship. Because of that, I will incorporate witness data into our analysis.
NYPD internal structure as it relates to our data
The NYPD is divided into coverage areas within the 5 boroughs known as precincts. When I lived in Brooklyn, I lived in the 81st Precinct which covers Bed-Stuy.
The NYPD also has a number of units, like the Warrant Squad or Narcotics that span different precincts. An officer might report to a numbered precinct, but their command is Brooklyn Narcotics, and they are interacting with other officers in their unit more than the precinct they work out of. Our data reflects this.
Analysis
Overview exploration / metadata
The source dataset is an 81.2MB excel file that I received as FOIL2021-00167_Dataset.xlsx. It has 3 tabs. The first has some general notes1 about the dataset.
The first tab has the title of OfficerAllegationHistory and has 181,627 entries and 472 columns.
The second tab has the title of OfficersInvolvedInComplaints and has 239,608 entries and 183 columns.
Analyzing our data with Datasette / SQLite
Once we convert our CSV files into SQLite .db files we can use Datasette to get a sense of the data and slice off pieces for further analysis.
The first thing we might want to look at is the top commands that received complaints since 2010.
select [Officer Command At Incident], count([Officer Command At Incident]) from OfficerAllegationHistorywhere [Incident Date] BETWEEN '2010-01-01' AND '2010-12-31'group by [Officer Command At Incident] order by count([Officer Command At Incident]) DESC LIMIT 5
075 PCT: 320
046 PCT: 251
047 PCT: 226
120 PCT: 199
BX IRT : 196
Or the top 10 commands whose complaints ended in penalties.
select [Officer Command At Incident], count([Officer Command At Incident]) from OfficerAllegationHistorywhere [Incident Date] BETWEEN '2010-01-01' AND '2021-12-31'AND [CCRB Allegation Disposition] = 'Substantiated (Charges)'group by [Officer Command At Incident] order by count([Officer Command At Incident]) DESC LIMIT 5
WARRSEC: 91
PBBX : 84
081 PCT: 71
079 PCT: 70
075 PCT: 68
After using Datasette to get a sense for the shape of our dataset, we can use it to filter out a slice of the data to use to feed into our next tool and begin doing our network analysis.
Ian Johnson helped me explore the data a bit in Observable as well.
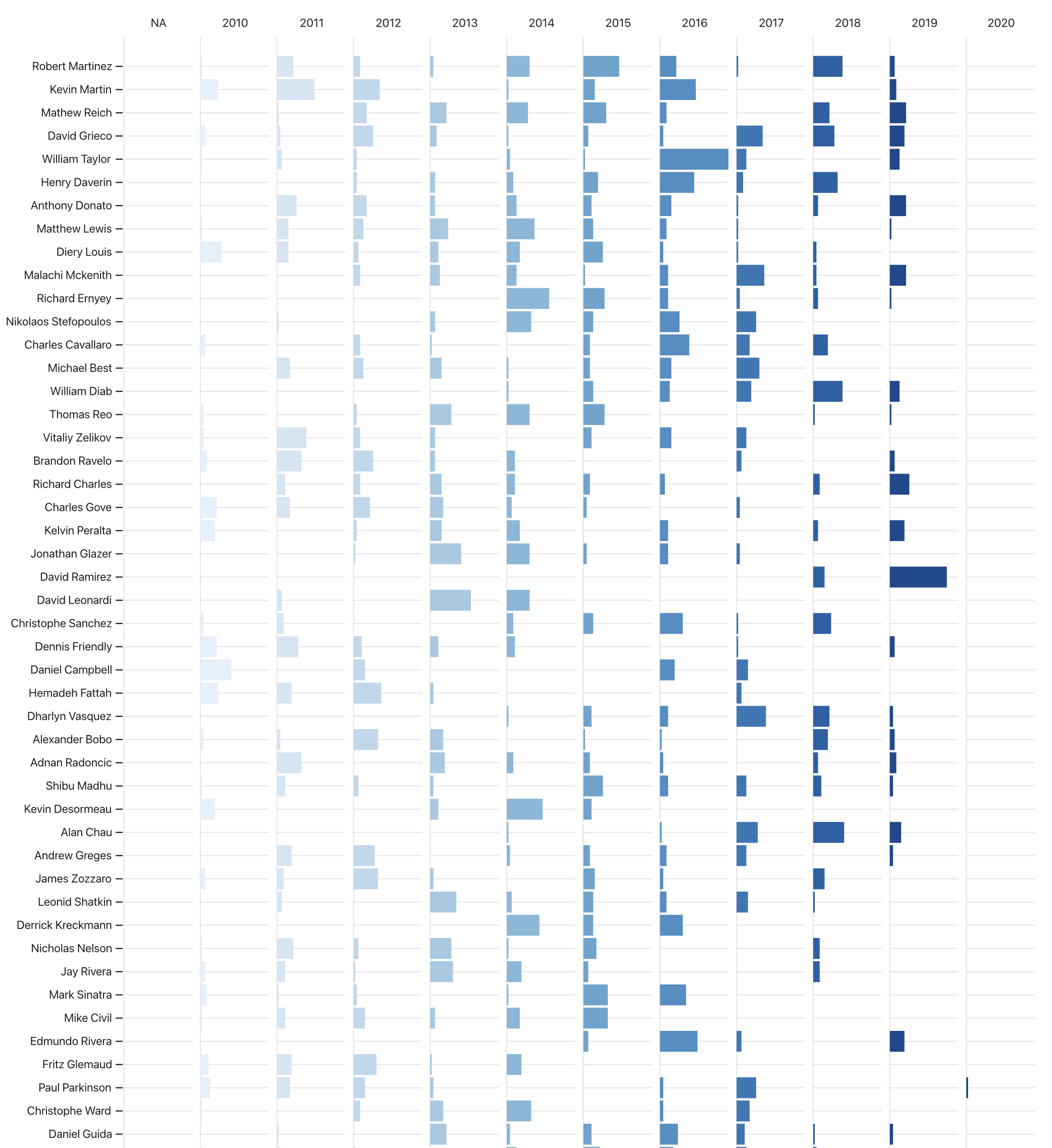
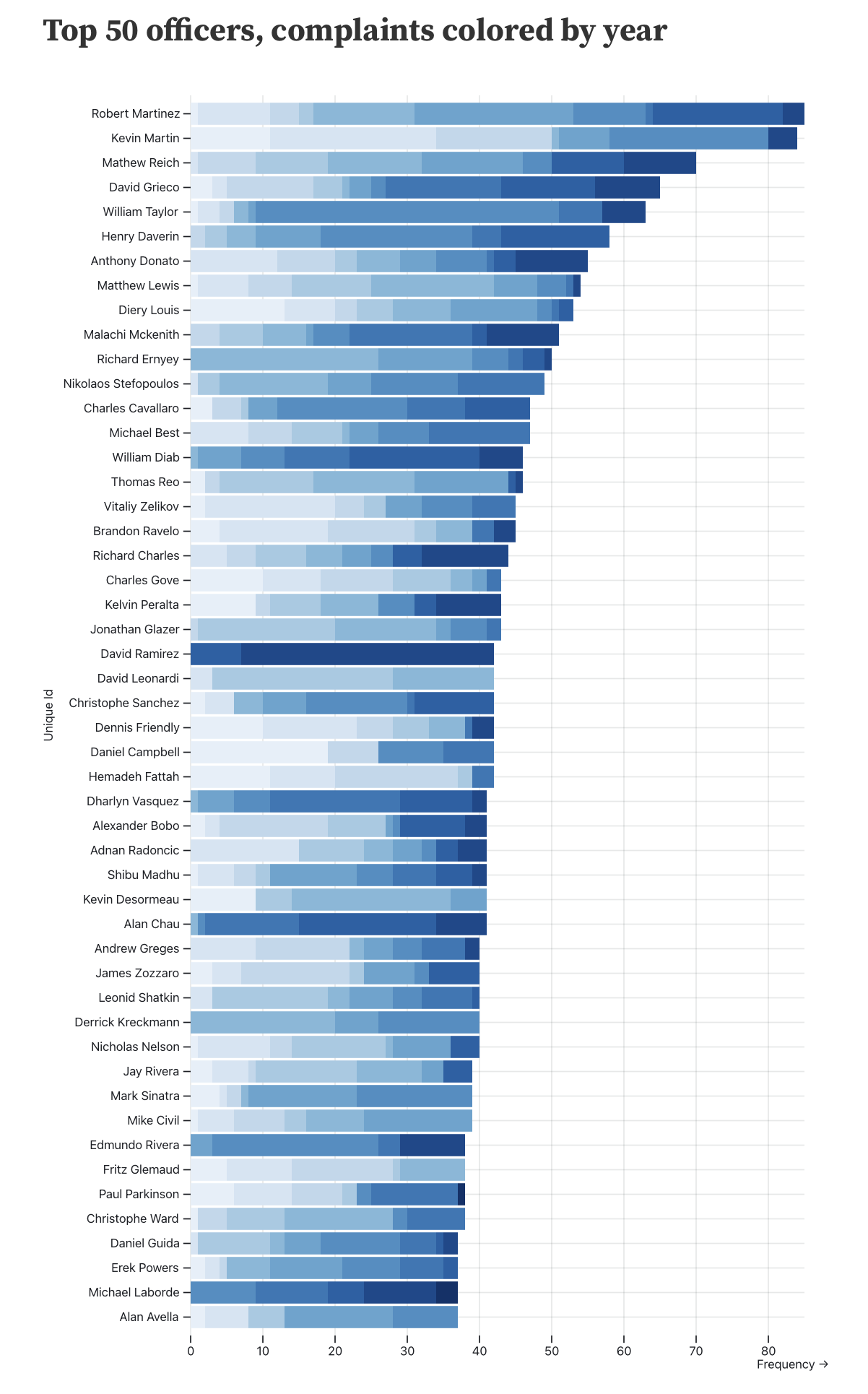
We looked at when officers received complaints. Here each year is split into a bar. We are showing the officers who received the most complaints in the entire dataset.
Or stacking the bars- the darker they are, the more recent the complaints occurred.
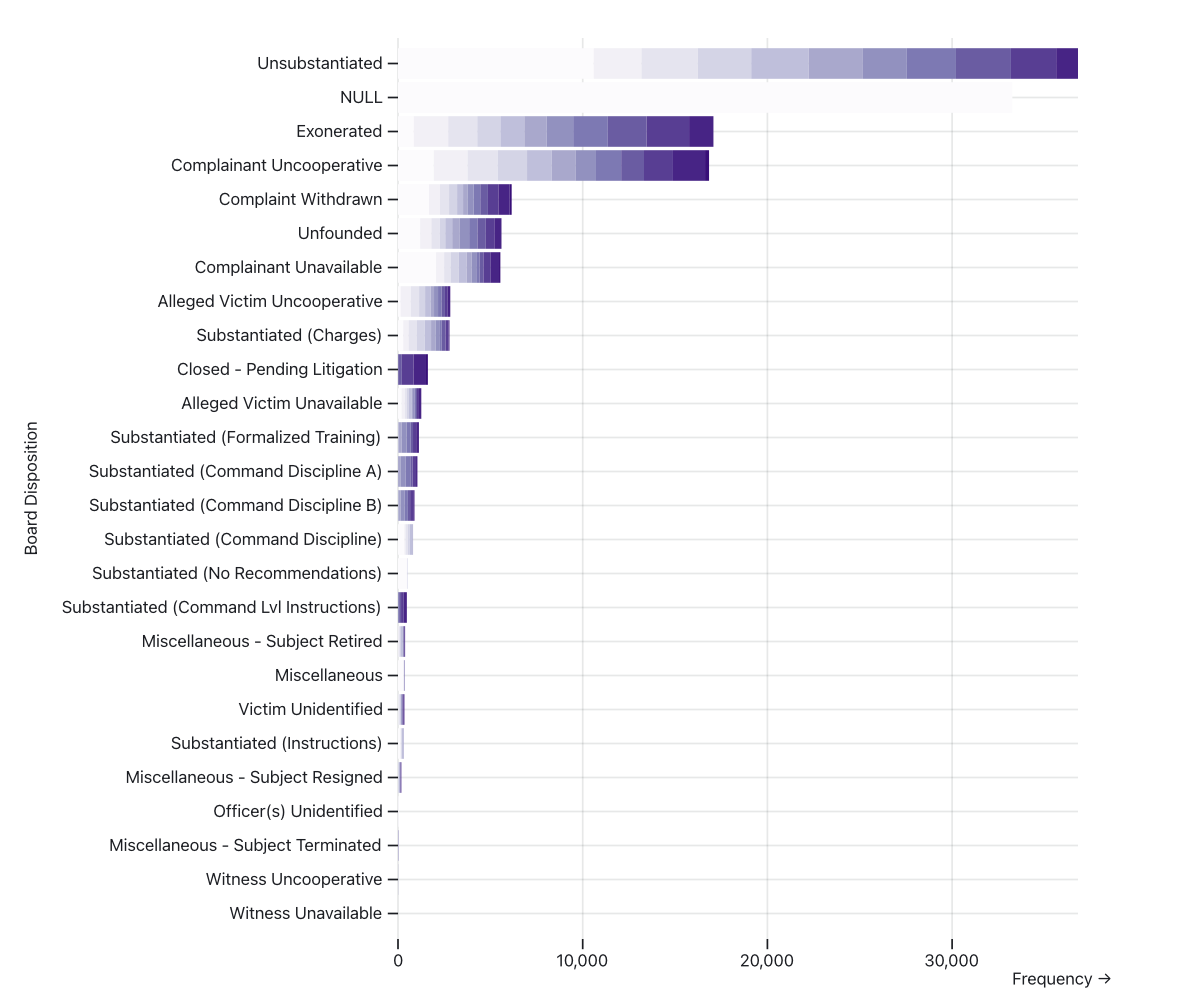
You can also look at the CCRB outcomes and see how rarely cases are substantiated or end in discipline.
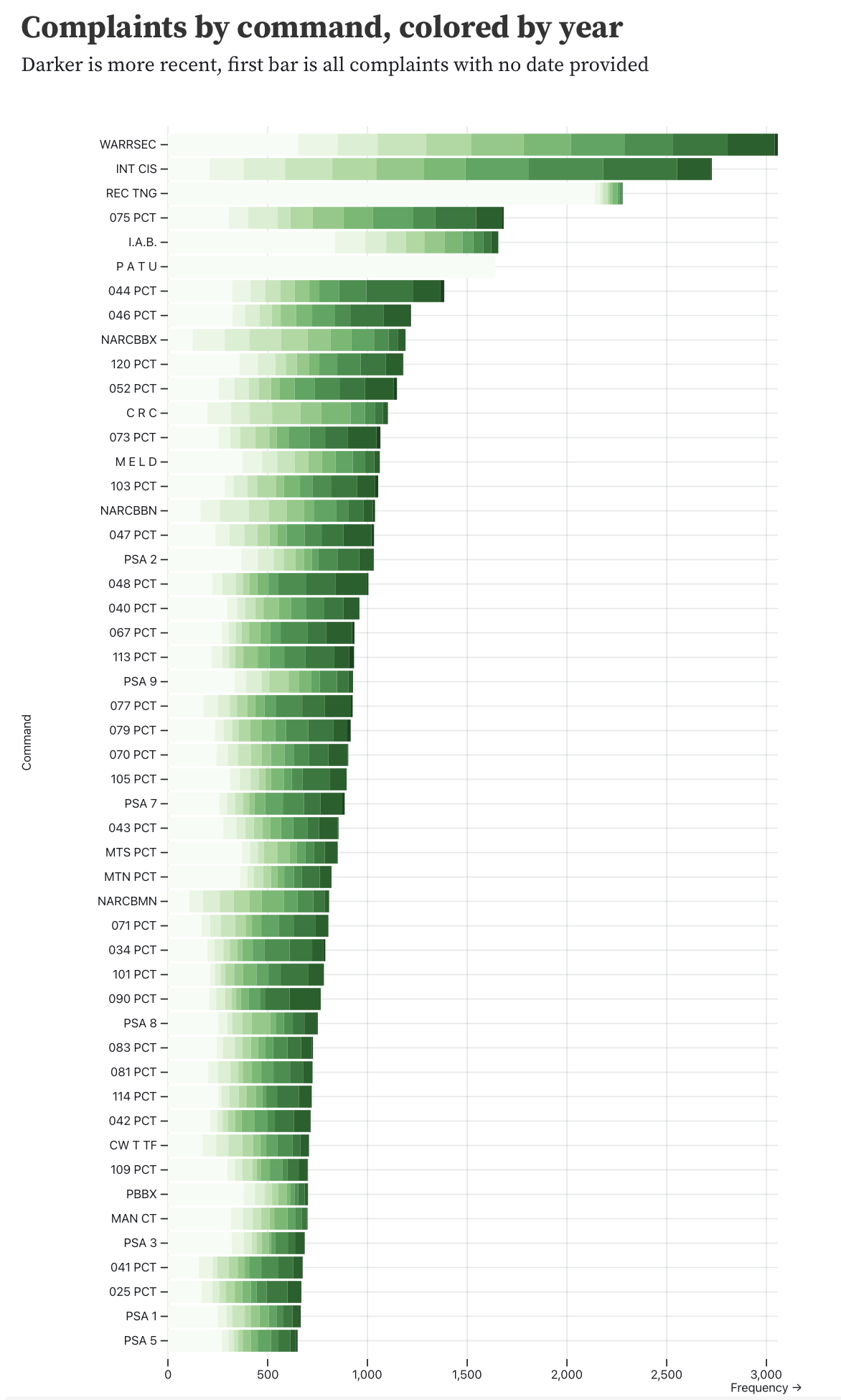
We also looked at which commands received the most complaints across the entire dataset.
Filtering out "Exonerated" and "Unfounded" complaints for our network
To get our network closer to a representation of officers who are receiving complaints for misconduct we want to filter out any of the cases in which the officer was Exonerated or the CCRB's disposition was that it was Unfounded.
So to get every complaint filed since 2010 that wasn't marked as exonerated or unfounded we'll write a query like
select * from OfficerAllegationHistorywhere ([Incident Date] BETWEEN '2010-01-01' AND '2021-12-31') AND ([CCRB Allegation Disposition] IS NOT 'Exonerated'AND [CCRB Allegation Disposition] IS NOT 'Unfounded')
Which gives us a slightly more manageable 65,401 rows. We'll save these results off as a .csv for further analysis.
I had to do some funky stuff3 to fix the dates in SQLite, but once I did that, it was easy to filter by the date column.
We can also export new CSVs for all of the incidents since 2010 for a particular precinct:
select * from OfficerAllegationHistorywhere [Incident Date] BETWEEN '2010-01-01' AND '2021-12-31' AND [Officer Command At Incident] = '075 PCT'
These precinct-specific slices are a bit smaller and more manageable for analysis in Observable.
We'll also want to export another CSV with ONLY complaints that were substantiated
select * from OfficerAllegationHistorywhere ([Incident Date] BETWEEN '2010-01-01' AND '2021-12-31') AND ([CCRB Allegation Disposition] IS 'Substantiated (Charges)' OR [CCRB Allegation Disposition] IS 'Substantiated (Command Discipline A)'OR [CCRB Allegation Disposition] IS 'Substantiated (Command Discipline B)'
It is an incredibly useful tool for generating and analyzing networks, and I was excited to have another dataset that would let me use its considerable power.
Importing our CSV with Cypher
To import our .csv into a network of node and relationships in Neo4J, we will use the Cypher query language, which makes this process really easy and the code is relatively readable and easy to follow.
Special thanks to David Allen at Neo4J for his guidance in writing queries and designing these relationships.
Basically we take the CSV files we exported from Datasette (when we filtered our Exonerated, Unfounded, and everything before 2010) and go through every row and push it into our network.
Creating officer nodes
First we tell Neo4J to use officer.id as a unique constraint (this makes things faster, I think?) and create a node for each officer from one CSV.
CREATE CONSTRAINT officerIdConstraint ON (officer:Officer) ASSERT officer.id IS UNIQUE
Then I loop through every line of the .csv and create a new Officer node for every new officer I see. I use MERGE instead of CREATE to make sure I don't duplicate officer nodes.
LOAD CSV WITH HEADERS FROM "http://localhost:11001/project-185bb75c-b944-451a-9c0f-aeba860ae68a/OfficersInvolvedInComplaints_FILTERED-SINCE2010-NOT-UNFOUNDED-EXONERATED.csv" AS csvLineMERGE (officer:Officer {id: csvLine.`Unique Officer Id`, lastName: csvLine.`Officer Last Name`, firstName: csvLine.`Officer First Name`, OfficersInvolvedInComplaints: true})RETURN officer
This creates 29,915 unique officer nodes.
Then we bind more data into it from our other CSV
LOAD CSV WITH HEADERS FROM "http://localhost:11001/project-185bb75c-b944-451a-9c0f-aeba860ae68a/OfficerAllegationHistory.csv" AS csvLineMERGE (officer:Officer {id: csvLine.`Unique Officer Id`, lastName: csvLine.`Officer Last Name`, firstName: csvLine.`Officer First Name`, shieldNo: csvLine.`Shield No`, currentRank: csvLine.`Current Rank`, currentCommand: csvLine.`Current Command`, OfficerAllegationHistory: true})RETURN officer
Finally, we need to add a boolean to denote if an officer has ever had a charge substantiated. We'll use this later to please some lawyers. You'll see.
LOAD CSV WITH HEADERS FROM "http://localhost:11001/project-185bb75c-b944-451a-9c0f-aeba860ae68a/OfficerAllegationHistory_FILTERED-SINCE2010-SUBSTANTIATED.csv" AS csvLineMERGE (officer:Officer {id: csvLine.`Unique Officer Id`})SET officer.ccrbSubstantiatedBool = "true"RETURN officer
Now we've marked 4,768 of New York's ~36,000 (13%) finest as having a substantiated complaint in the last 10 years.
Let's NOT do the same thing for OfficersInvolved - because that file contains officers who were merely witnesses to substantiated complaints, and we don't want to accidentally label a witness to a substantiated case.
Creating officer labels
Now we need to set labels for our nodes depending on whether they have ever had a complaint substantiated. We don't want to label nodes with names for any officers who may have complaints but have never had any substantiated. I have been told that lawyers think this is a good idea.
First we set every officer label to their unique ID
MATCH (o:Officer)SET o.label = o.id
Then we look for officers with substantiated complaints and set their label to their full name.
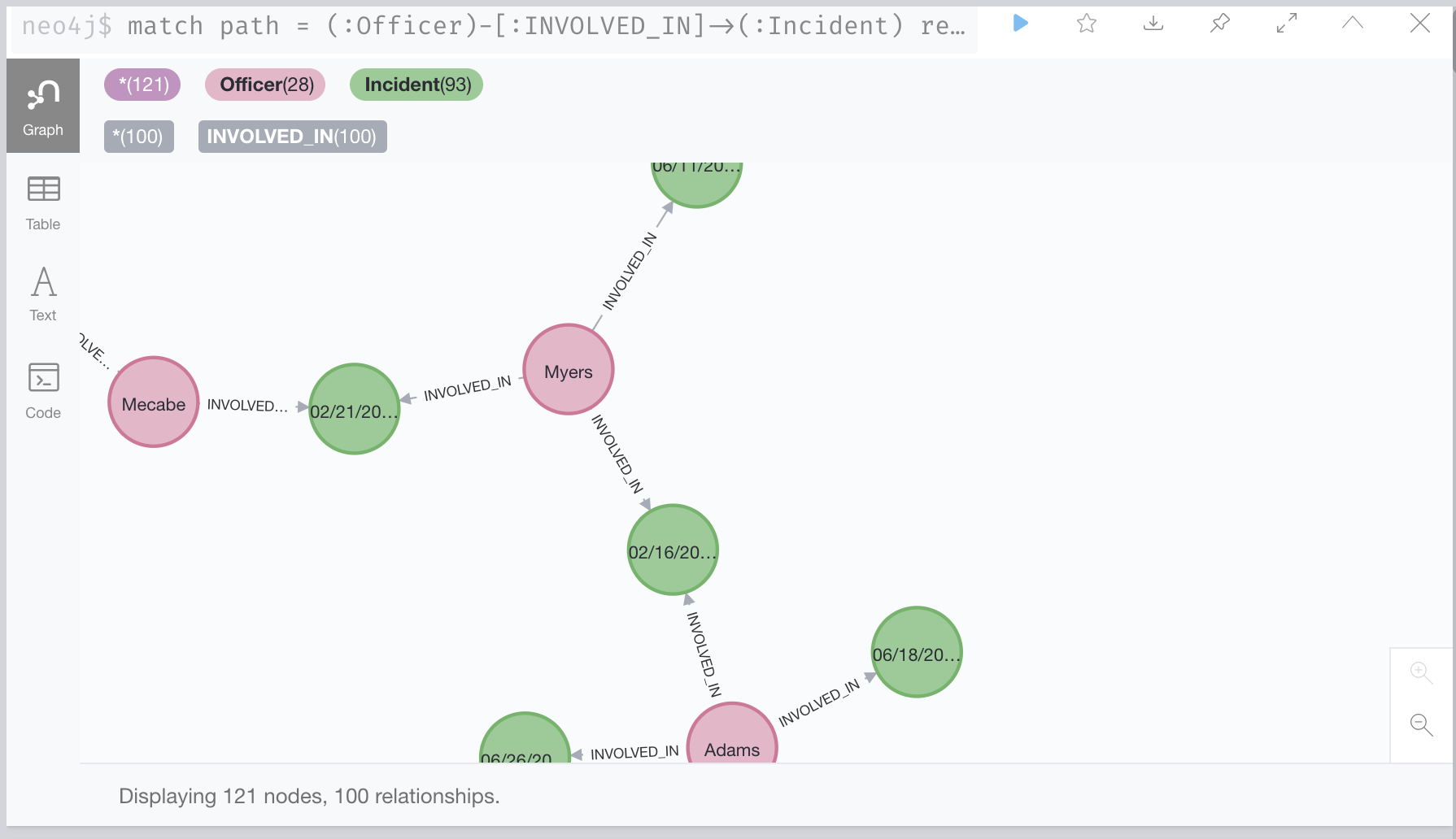
Now we have our officers created, we need to create our incidents.
Creating incident nodes
We are going to continue to use our CSV which filtered out incidents before 2010 or that were unfounded or exonerated.
First we tell Neo4J that we have unique incident IDs
CREATE CONSTRAINT incidentIdConstraint ON (incident:Incident) ASSERT incident.id IS UNIQUE
Then we create an incident for every row we see in OfficerAllegationHistory. We'll make note of the precinct the incident occurred in, what the specific allegation was, and what date the incident occurred.
LOAD CSV WITH HEADERS FROM "http://localhost:11001/project-185bb75c-b944-451a-9c0f-aeba860ae68a/OfficerAllegationHistory_FILTERED-SINCE2010-NOT-UNFOUNDED-EXONERATED.csv" AS csvLineMERGE (incident:Incident {id: csvLine.`Complaint Id`})SET incident.incidentPct = COALESCE(csvLine.`Precinct Of Incident Occurrence`,"N/A")SET incident.ccrbDisposition = csvLine.`CCRB Allegation Disposition`SET incident.allegation = csvLine.`Allegation`set incident.date = csvLine.`Incident Date`RETURN incident
Now let's do the same for OfficersInvolvedInComplaints.
LOAD CSV WITH HEADERS FROM "http://localhost:11001/project-185bb75c-b944-451a-9c0f-aeba860ae68a/OfficersInvolvedInComplaints_FILTERED-SINCE2010-NOT-UNFOUNDED-EXONERATED.csv" AS csvLineMERGE (incident:Incident {id: csvLine.`Complaint Id`})SET incident.ccrbDisposition = csvLine.`Complaint Disposition`RETURN incident
Now let's create labels for our incidents, which is going to be the allegation.
MATCH (i:Incident)SET i.label = i.allegation
Now that we have our Incidents and our Officers we need to create our relationships between them.
Creating relationships between incidents and officers
Now for the fun part.
We are going to create a new relationship called INVOLVED_IN, and officers can be INVOLVED_IN one or many incidents. Incidents may have one or many officers that were INVOLVED_IN it, either as witness or subject officers.
First we create our relationships from OfficersInvolved:
LOAD CSV WITH HEADERS FROM "http://localhost:11001/project-185bb75c-b944-451a-9c0f-aeba860ae68a/OfficersInvolvedInComplaints_FILTERED-SINCE2010-NOT-UNFOUNDED-EXONERATED.csv" AS csvLineMATCH (officer:Officer {id: csvLine.`Unique Officer Id`}) with csvLine, officerMATCH (incident:Incident {id: csvLine.`Complaint Id`}) with csvLine, officer, incidentCREATE (officer)-[:INVOLVED_IN {status: csvLine.`Officer Status`}]->(incident)
Which creates 94,323 relationships.
Then from OfficerAllegationHistory:
LOAD CSV WITH HEADERS FROM "http://localhost:11001/project-185bb75c-b944-451a-9c0f-aeba860ae68a/OfficerAllegationHistory_FILTERED-SINCE2010-NOT-UNFOUNDED-EXONERATED.csv" AS csvLineMATCH (officer:Officer {id: csvLine.`Unique Officer Id`}) with csvLine, officerMATCH (incident:Incident {id: csvLine.`Complaint Id`}) with csvLine, officer, incidentCREATE (officer)-[:INVOLVED_IN {allegation: csvLine.`Allegation`, type: csvLine.`FADO Type`}]->(incident)
Now we have 159,671 relationships. Sick.
Next we can flatten out our graph a little bit and remove incidents if we want.
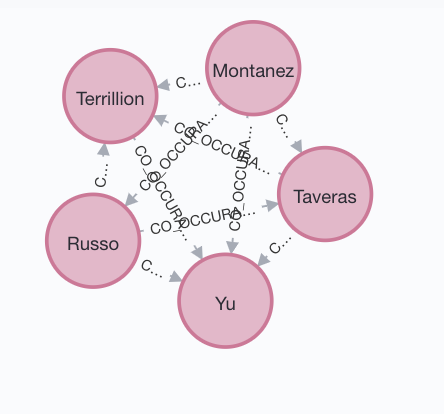
We will create a new type of relationship that only occurs between two officers called CO_OCCURANCE - we will only make one of these between each officer, but the weight of that link will be decided by how many complaints those officers appear together on.
So officers who appear on 3 complaints together have a CO_OCCURANCE relationship with a weight of 3. This allows us to do some weighted degree analysis when we are making our layout, deciding how large to make nodes, and when we are detecting communities.
MATCH (o1:Officer)-[:INVOLVED_IN]->(i:Incident)<-[:INVOLVED_IN]-(o2:Officer) WHERE id(o1)<id(o2) with o1, o2, count(i) as weightCount CREATE (o1)-[:CO_OCCURANCE { weight: weightCount }]->(o2)
Officers without connections
MATCH (o:Officer) WHERE NOT (o)-[:CO_OCCURANCE]-() RETURN count(o)
Now every Officer node has an eigenvector value that represents its centrality across our entire NYPD-wide network. The larger the value, the more central that node is.
Analyzing our data with Gephi
Neo4J is cool for processing and analyzing tons of data, but I want to draw thousands of circles and lines now and start untangling the hairball of our network.
I am going to use Gephi, which I have a love-hate relationship with, but is unrivaled when it comes to network visualization. Plus, I already know how to use it.
We are going to stream our data from Neo4J to Gephi in order to leverage Neo4J's power to handle huge amounts of data (way more than Gephi) but still get to use Gephi's layout algorithms and analysis techniques.
Flattened co-occurance network
To get our flattened network, which removed incident nodes:
MATCH path=(o1:Officer)-[r:CO_OCCURANCE]->(o2:Officer) WITH o1, path limit 125000 with o1, collect(path) as paths call apoc.gephi.add(null,'workspace1', paths, 'weight', ['weight', 'id', 'eigenvector', 'firstName', 'lastName', 'label', 'date', 'currentCommand']) yield nodes, relationships, time return nodes, relationships, time ORDER BY o1.eigenvector DESC
This streams 100,000 edges and 25,064 nodes into Gephi.
We'll run the Force Atlas 2 layout algorithm in Gephi to have the nodes arrange themselves into some sort of sense.
We can use Gephi's modularity algorithm to color by "community" within our network, and we'll tweak our layout algorithm to separate things out a bit.
The communities that Gephi detects often mirror real-world precincts. As one might expect, officers appear on complaints with other officers in their precinct because they are working together most often.
I like that the algorithm detects communities that resemble precincts, and it actually gives me confidence that the community detection is working.
Then we can add some labels and we've made a map of the network of officers who appeared on CCRB complaints together, and there appear to be a number of closely-knit clusters and different communities within our network.
Precinct-specific networks including incidents (un-flattened network)
Let's put it all together and stream all the officers from a single precinct using only incidents since 2010.
MATCH path=(o1:Officer)-[:INVOLVED_IN]->(i:Incident {incidentPct: "75"})<-[:INVOLVED_IN]-(o2:Officer)where i.date IS NOT NULL and apoc.date.parse(i.date, "ms", 'YYYY-mm-dd') > 1262304000000 WITH o1, path, i limit 100000 with o1, i, collect(path) as paths call apoc.gephi.add(null,'workspace1', paths, 'weight', ['weight', 'id', 'eigenvector', 'firstName', 'lastName', 'date']) yield nodes, relationships, time return nodes, relationships, time ORDER BY o1.eigenvector DESC
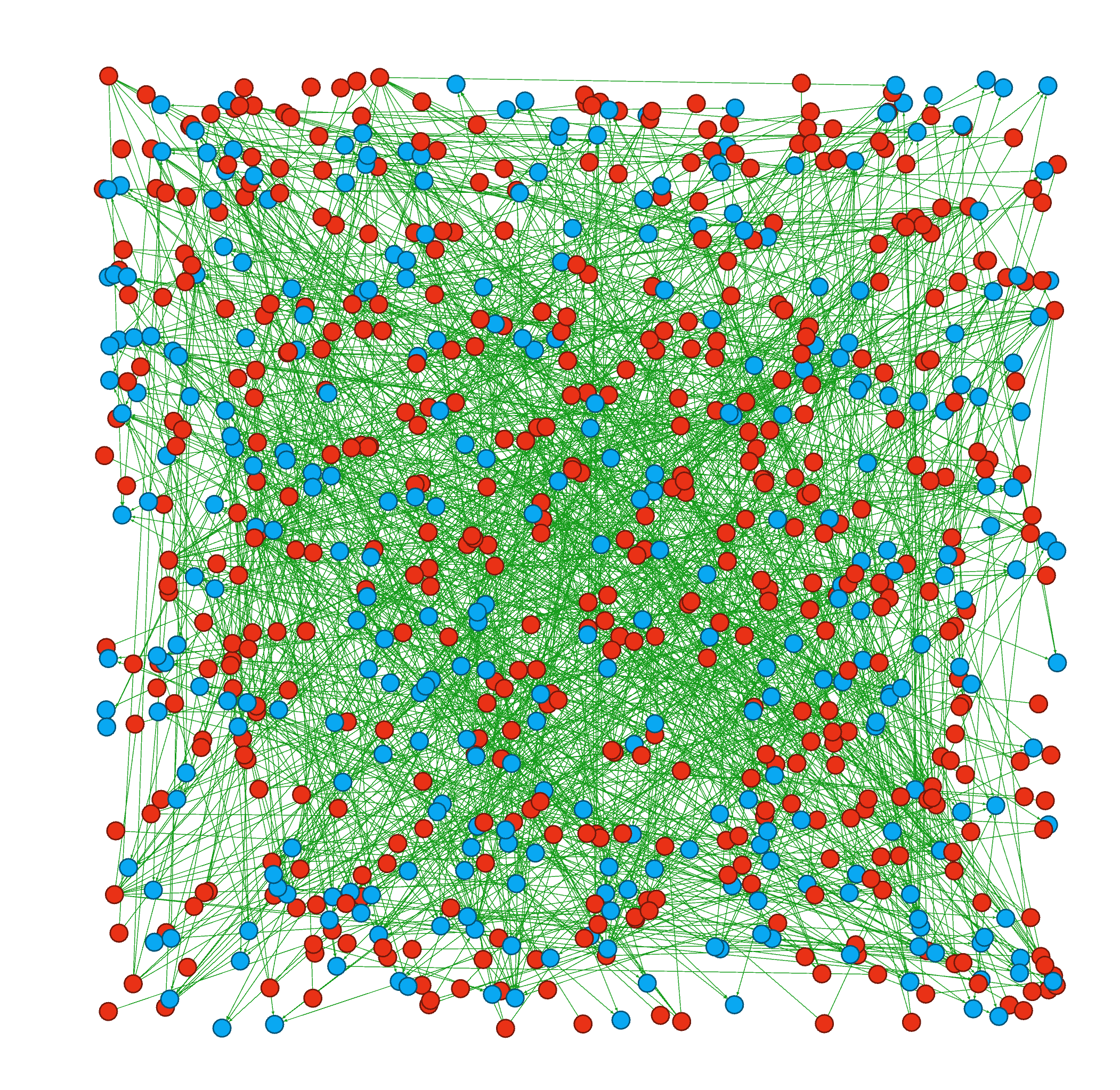
We can also make a network that is un-flattened, that is, we can see nodes for both officers as well as incidents. This way, we can see the patterns in the way incidents tie officers together.
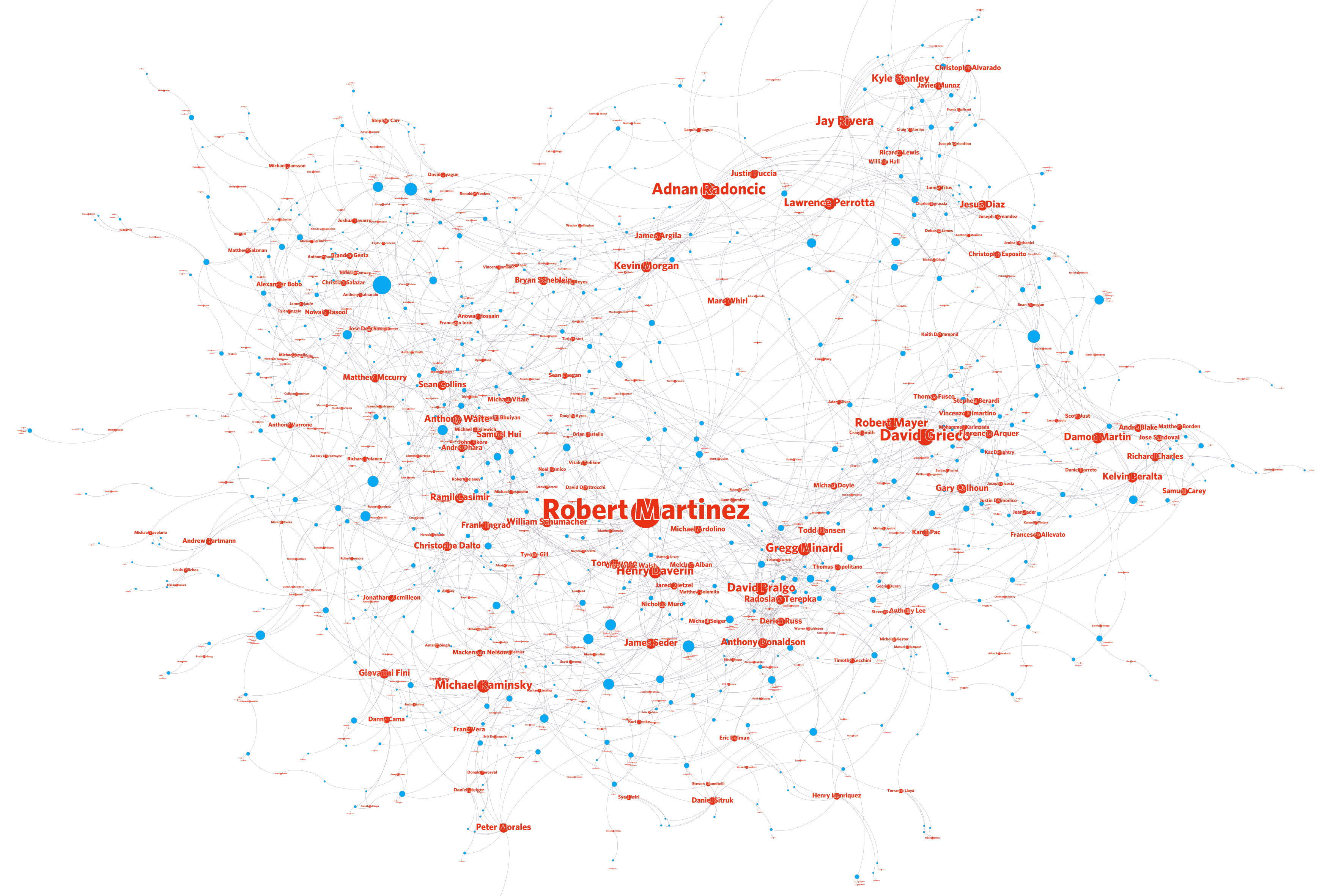
Every blue circle here is an incident, and every red circle is an officer (both filtered by the 75th precinct, since 2010).
Now let's size the circles by their degree (the number of connections they have) and run a layout algorithm.
Some big nodes start to pop up, like Martinez, Radoncic, and Grieco. What is causing these officers to co-appear on so many different complaints with so many different officers?
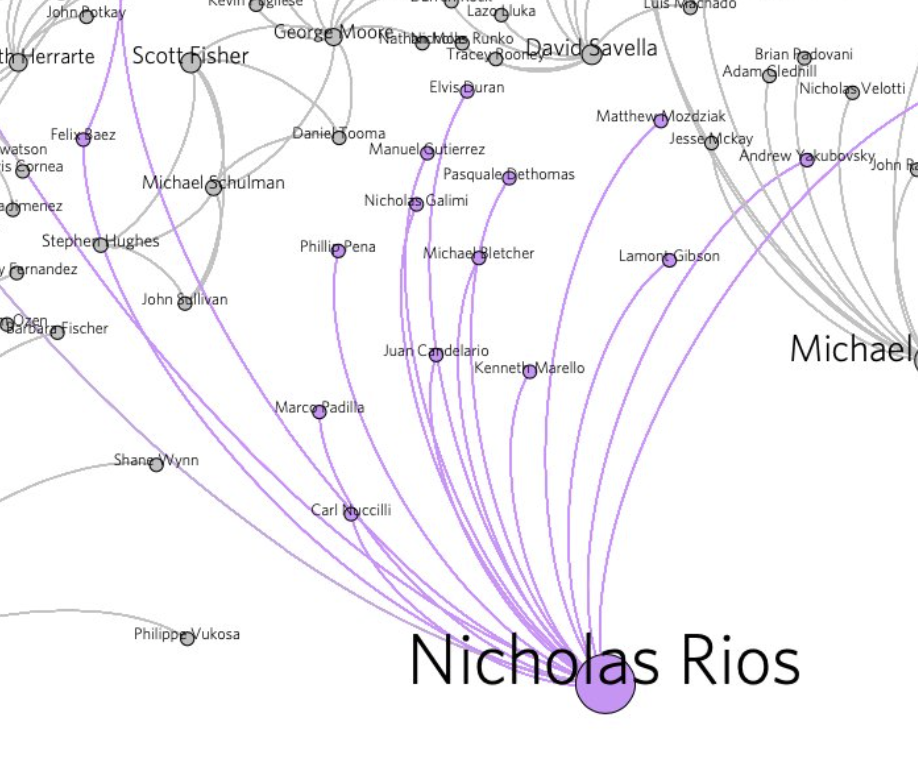
When exploring this network, large nodes pop up, and I became naturally curious what the careers of those officers looked like. One of the first ones that jumped out to me was a big node that represented an officer named Nicholas Rios.
I googled his name, and one of the first results was a harrowing story of a federal civil rights case that named him.
In the reporting that George Joseph did for Gothamist/WNYC, he found that a number of large influencers that appear in this network analysis also acted as influencers on the ground.
He looked at another large node in the network, Adnan Radoncic:
Atunbi asserted that Radoncic was a catalyst for a group assault on the street that day.
“As soon as he grabbed me, all the officers was hands on,” he said. “It’s like they just followed his lead.”
Potential Next Steps
There are a few different directions for further analysis that I didn't have time for, but may result in interesting findings.
Explorable NYPD-wide network
Looking at protest complaints
Looking at veterans influencing rookies
Looking at the effects of NYPD discipline
Officer career-specific visualization
Analysis of length/outcomes of CCRB investigations
Geographic analysis
Flotsam & Jetsam
Hire me to do work like this
I do freelance data exploration and visualization for clients who aren't evil. If you'd like to hire me to take a look at a dataset for you, just get in touch at [email protected]
Footnotes
The notes say, basically: these are complaints received in or after the year 2000. Cases that are mediated or were attempted to be mediated are excluded. ↩